
#Dobras 30 // Meus algoritmos acham que estou grávida? Notas sobre predição e influência de comportamento online
7 de maio de 2019Por Anna Bentes


Meus algoritmos acham que estou grávida?
Recentemente, comecei a receber alguns anúncios relacionados à gravidez, à maternidade e a crianças de uma forma geral: de anúncios de exercícios para mulheres grávidas, roupas para amamentação a sugestões de escolas para Educação infantil, passando por diversos outros conteúdos relacionados a bebês e a crianças, tanto apresentando recomendações ou dicas até simplesmente vídeos fofos de crianças com pais ou avós.
Surpresa e intrigada, a primeira coisa que me lembrei foi aquela clássica história para quem estuda vigilância sobre o pai que descobre que a filha estava grávida depois de notar que ela recebeu ofertas de produtos para bebês [1]. Ainda no início de 2012, antes das primeiras evidências ligadas às práticas de vigilância em massa na internet que seriam reveladas por Edward Snowden no ano seguinte e quando pouco se falava sobre algoritmos, big data ou sistemas de recomendação, esse pai vai a uma das unidades da rede de lojas de varejo Target em Minneapolis, nos Estados Unidos, realizar uma reclamação. Segundo ele, sua filha, que ainda estava no Ensino Médio, tinha recebido cupons de roupas para bebes e berços por e-mail pela loja. Revoltado, ele pergunta ao gerente se estavam “tentando encorajar sua filha a engravidar”. Sem entender bem o que tinha acontecido, o gerente da loja liga alguns dias depois para o homem a fim de pedir desculpas, mas é surpreendido com a seguinte declaração do pai: “Eu tive que falar com a minha filha e parece que aconteceram algumas atividades em minha casa que eu não estava ciente, eu é que te devo desculpas”.
Esse caso ficou conhecido, sobretudo, por ser um dos primeiros exemplos de sistemas de recomendação personalizada a partir de práticas de vigilância na internet, mas que eram pouco conhecidas ou faladas até então. Embora o modo de funcionamento dos mecanismos vigilância e dos sistemas automatizados de recomendação já tenham se atualizado bastante desde aquela época, esse caso também aponta para um questionamento ainda pertinente até hoje: a partir desse monitoramento contínuo dos rastros de nossas ações online, as tecnologias estariam sendo capazes de prever nosso comportamento? Ou será que, como o próprio pai suspeitou, os sistemas de vigilância e recomendação estariam mais preocupados em “encorajar”, estimular ou produzir certos comportamentos do que efetivamente prevê-los? Ainda, será que esses sistemas são realmente capazes de predizer uma gravidez ou mesmo de influenciar alguém a engravidar?
Me parece que temos aí uma questão importante em relação a como operam hoje os sistemas algorítmicos de recomendação e também toda a economia digital. Embora a gente saiba muito pouco sobre como os sistemas algorítmicos de inteligência artificial de fato funcionam, talvez, não haja efetivamente uma oposição entre predição e influência de comportamento, mas sim duas faces de mecanismos que se entrecruzem.
Em seu livro mais recente, Shoshana Zuboff descreve e analisa as mutações na lógica do capitalismo a partir das tecnologias digitais. Em sua análise sobre o que chama de capitalismo de vigilância, a autora enfatiza justamente a associação entre mecanismos de predição e de influência de comportamento como uma das principais caraterísticas dessa nova lógica de acumulação. Segundo ela,
O capitalismo de vigilância reivindica unilateralmente a experiência humana como matéria-prima disponível e acessível gratuitamente para ser traduzida em dados comportamentais. Embora parte desses dados sejam aplicados para o aprimoramento dos produtos ou serviços, o resto desses dados é transformado em excedente comportamental proprietário, que fomenta processos de produção avançados conhecidos como “inteligência de máquina” e fabrica produtos de predição que antecipam o que você fará agora, em breve e depois. Finalmente, esses produtos de previsão são negociados em um novo tipo de mercado para o que chamo de mercados de comportamento futuro. (…) a dinâmica competitiva desses novos mercados impulsiona os capitalistas de vigilância a adquirirem fontes cada vez mais preditivas de excedente comportamental: nossas vozes, personalidade e emoções. Por fim, os capitalistas de vigilância descobriram que os dados comportamentais mais preditivos são adquiridos a partir da intervenção no curso da ação [state of play], a fim de estimular, ajustar e persuadir o comportamento na busca de resultados lucrativos. Pressões competitivas produziram essa mudança, na qual processos maquínicos automatizados não apenas conhecem nosso comportamento, mas também moldam nosso comportamento em escala. Com essa reorientação do conhecimento para o poder, não é mais suficiente automatizar os fluxos de informação sobre nós; o objeto agora é nos automatizar. Nessa fase do desenvolvimento do capitalismo de vigilância, os meios de produção estão subordinados a um “meio de modificação comportamental” cada vez mais complexo e abrangente (ZUBOFF, 2019, p. 14-15, grifos da autora). [2]
Nessa intrigante definição, Zuboff sugere que as transformações na lógica de acumulação capitalista atual introduzem “meios de modificação comportamental” a partir de “produtos de predição”. Nesse sentido, é a partir do acúmulo de informações extraídas da vigilância contínua sobre nossas ações que os serviços da internet extraem o “excedente comportamental”, isto é, quaisquer tipos de dados e/ou metadados sob os quais são aplicadas técnicas computacionais inteligentes para se extrair predições de nossas ações futuras. Segundo ela, quanto maior a acuidade preditiva desses sistemas, maior será seu valor de mercado e, por sua vez, maior o potencial de influenciar aquela ação.
Nessa equação econômica, o perfil de cada usuário, formado a partir da coleta, acúmulo e análise ininterrupta de seus dados, é um elemento fundamental, uma vez que ele poderá definir as estratégias e os meios de modificação do comportamento. Dentro dessa lógica, o objetivo da geração de tais perfis está menos ligado a produção de um saber individualizado, unificado e aprofundado da personalidade de indivíduos específicos e identificáveis do que usar um conjunto de informações e correlações interpessoais para agir sobre seus similares. Deste modo, como aponta Fernanda Bruno (2013, p.161), um perfil “é uma categoria que corresponde à probabilidade de manifestação de um fator (comportamento, interesse, traço psicológico) num quadro de variáveis”, funcionando mais como uma simulação da identidade do que a representação fiel ancorada num referente da realidade. Nesse mesmo sentido, John Cheney-Lippold (p. 67) enfatiza que a identidade algorítmica é baseada em “interpretações quase em tempo real de [nossos] dados” e, por isso, são incessantemente atualizadas a cada clique, a cada visita a um novo site, a cada acesso ou login em alguma plataforma ou até a cada ausência de interação. Por exemplo, sugere o autor (p.71), o gênero de um usuário pode ser “92% masculino às 9:30pm, mas oito horas depois, às 5:30am, após uma noite de sono sem visitar novos sites, esse usuário pode ser agora 88% masculino”.
Assim, a partir da correlação de inúmeras informações que se atualizam a cada instante sobre os usuários, os perfis pretendem revelar padrões supra-individuais ou inter-individuais que permitam fazer predições em larga escala. Deste modo, os sistemas de recomendação algorítmicos buscam definir os perfis de alvos específicos para sugestão de conteúdos diferenciados no momento apropriado para influenciar, de forma personalizada e em tempo real, o comportamento dos usuários (INTRONA, 2016). E, a partir disso, são realizados ininterruptamente diversos experimentos a fim de testar formas mais efetivas para direcionar a atenção e o comportamento dos usuários: desde pequenas variações nos títulos, no tom, ou tamanho de textos, até alterações de horários, de imagem, cores, vídeos etc. Esse tipo de ajuste específico dos contextos nos quais as decisões são tomadas a fim de influenciar o comportamento em certa direção tem sido chamado pelos economistas comportamentais de “arquitetura de decisões” (NADLER & MCGUIGAN). Na estrutura das plataformas digitais, as técnicas da arquitetura de decisões podem envolver adaptações na interface, no design de softwares, nos recursos técnicos das próprias plataformas, até os modelos de previsibilidade que definem o quê, como, quando, onde e a quem certos conteúdos são apresentados.
Embora grande parte do discurso do marketing digital, que utiliza as técnicas da arquitetura de decisões, justifique suas estratégias pela promessa de ofertar produtos, serviços e conteúdos ultrapersonalizados a um sujeito apto a tomar decisões racionais, na verdade, essas mesmas estratégias estão ancoradas em referências teóricas da economia comportamental e outros saberes da psicologia e das neurociências que parecem ter um modelo de sujeito que toma decisões de forma “previsivelmente irracional” (SEAVER, 2018; ARIELY, 2008). Ao tomar os sujeitos dessa forma, essas técnicas buscam explorar as vulnerabilidades cognitivas e emocionais dos usuários, a fim de influenciar e persuadir suas escolhas e comportamentos. E um dos principais objetivos na elaboração das estratégias dessa arquitetura de decisões é fazer com que o uso de plataformas ou sites não seja apenas um comportamento pontual, mas que se torne um hábito, isto é, “comportamentos automáticos desencadeados por pistas situacionais: coisas que fazemos com pouco ou nenhum pensamento consciente” (EYAL, 2014). Pois, na dinâmica econômica da internet, quanto mais tempo se passa enganchado e engajado em um serviço, maior será o acúmulo de dados e, por sua vez, de excedente comportamental, como aponta Zuboff.
Em vista disso, vale ressaltar que, não à toa, o perfil de uma mulher grávida desperta bastante a atenção e o interesse do mercado de marketing na internet, uma vez que a chegada de um filho ou de uma filha envolve a formação de hábitos de consumo de longo prazo. Por exemplo, se a mãe decide entre uma fralda da marca X ou Y, que será usada durante alguns anos da vida do bebê e, possivelmente, repetida, caso a mãe venha a engravidar de novo no futuro.
Desafiando todos as inesquiváveis e ubíquas técnicas de monitoramento digital, a pesquisadora Janet Vertesi [3] se propôs a realizar um experimento intrigante para tentar esconder de seus algoritmos que estava grávida. Segundo ela, o perfil de um usuário comum, normalmente, vale cerca de dez centavos de dólar no mercado de marketing digital, já o valioso o perfil de uma mulher grávida, pelo seu potencial de formação de hábitos, pode chegar a um dólar e cinquenta.
Para realizar esta árdua proposta, em primeiro lugar, Vertesi solicitou diretamente, por telefone, a amigos e familiares que não fizessem nenhum tipo referência ou menção a sua gravidez em redes sociais. Entre suas exaustivas medidas para despistar a vigilância online, ela utilizou exclusivamente o navegador Tor, que criptografa os dados de navegação e os distribui por diferentes servidores e, assim, garantindo o anonimato de seus usuários, para pesquisa e compras onlines de itens relacionados ao bebê. Além disso, outras medidas incluíram compras somente em dinheiro em espécie ou por cartões pré-pagos, a fim de evitar o rastreamento através do cartão de crédito, a criação de contas em endereço de e-mail privado, hospedado em servidor próprio, entre outras coisas.
Todas essas providências quase paranoicas (FALTAY, 2018) da pesquisadora deixam claro não somente que tentar sair do radar dos sistemas de monitoramento online é uma tarefa hercúlea atualmente, mas também que suas pegadas digitais podem, a depender do curso de seu comportamento ou escolha online, inseri-lo em um perfil específico e torna-lo um alvo valioso ou suspeito para certos tipos de mercados. Ao chamar atenção dos mecanismos automatizados, eles não somente vão tentar prever seus próximos passos como também direcionar, orientar e influenciar seu comportamento e escolhas futuras.
Talvez, não importe tanto se a predição revele ou represente um dado da realidade, mas sim o quanto certos índices de algo que pode ser inferido ou previsto efetivamente sirva para influenciar o comportamento. Pois, no universo automatizado, as máquinas produzem análises e tomam decisões, sobretudo, através de inferências estatísticas e de probabilidades. Nesta dinâmica, então, trata-se menos de critérios de verdade ou falsidade do que de performatividade. (SEYFERT & ROBERGE, 2016). Se uma predição, verdadeira ou falsa, conseguir definir os meios para alterar 5% de um determinado grupo ou população, isso já pode ser visto como um sucesso para esses sistemas. E, dependendo da escala, 5% pode ser bastante coisa ou o suficiente para produzir mudanças significativas na realidade. Por exemplo, eleger um presidente [4].
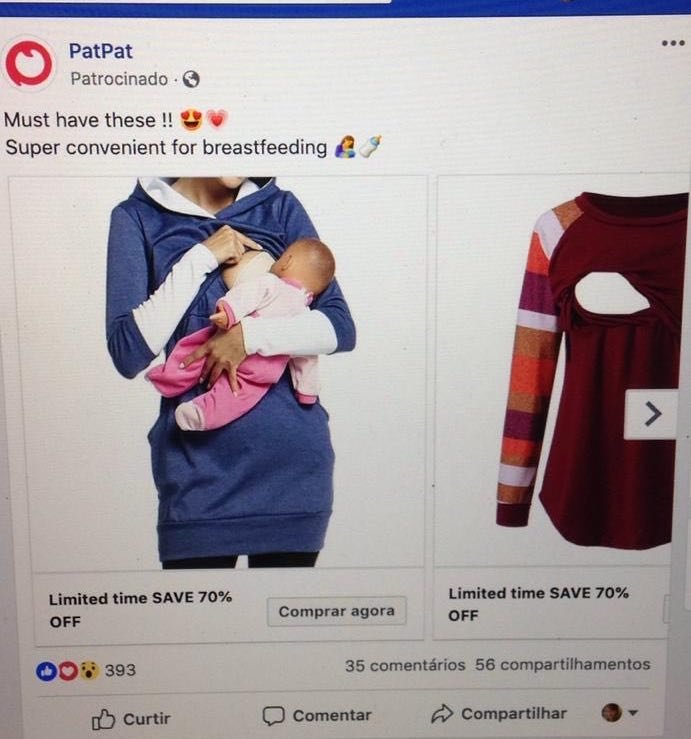

Portanto, o fato de receber anúncios de “exercícios para mulheres grávidas” não necessariamente indica uma previsão acurada de gravidez daquela usuária. Na lógica probabilística dos algoritmos e em sua gestão dos possíveis, o recebimento deste anúncio pode ter ocorrido por ela ter entrado, temporariamente, no perfil de “mulheres possivelmente grávidas”, mas também “mulheres que gostariam de engravidar”, “mulheres com idade X que que tendem a engravidar”, ou, ainda, “mulheres com idade X que realizaram uma pesquisa Y”, “mulheres que curtiram conteúdos relacionados a bebês ou crianças” e assim por diante.
Inúmeros tipos de cliques podem levar um usuário a receber um determinado conteúdo. Por vezes, ele pode ser apenas um teste e uma aposta do sistema em um “vai que cola”. Mas em outras ocasiões, certas pegadas digitais podem fazer com que um sistema de recomendação insista em certo tipo de conteúdo ou direção do comportamento, pois, ao apresentar e insistir com aqueles estímulos, ela estará influenciando, induzindo e conduzindo pouco a pouco a atenção, o interesse e comportamento do usuário. Pode ser que nenhuma mulher engravide porque recebeu anúncios de “roupas para amamentação”, mas a combinação desse tipo de anúncio com o recebimento diários de fotos ou vídeos de bebês fazendo coisas fofas, ao longo de um certo momento específico da vida daquela mulher, pode talvez, ao menos, despertar o desejo dela de ser mãe. E, se por acaso, ela for mãe, quem sabe decide comprar aquela marca “roupas para amamentação” ou decide realizar aqueles “exercícios para mulheres grávidas”. Essa é a aposta desse mercado.
Referências
ALTER, Adam. Irresistible: the rise of addictive technology and the business of keeping us hooked. New York, NY: Penguin Press, 2017.
BRUNO, Fernanda; CARDOSO, Bruno; KANASHIRO, Marta; GUILHON, Luciana; MELGAÇO, Lucas. Tecnopolíticas da vigilância: perspectivas da margem. São Paulo: Boitempo, 2018.
BRUNO, Fernanda. Máquinas de ver, modos de ser: vigilância, tecnologia e subjetividade. 1a Edição. Porto Alegre: Sulina, 2013.
______. A economia psíquica dos algoritmos: quando o laboratório é o mundo. Jornal NEXO Disponível em: <https://www.nexojornal.com.br/ensaio/2018/A-economia-ps%C3%ADquica-dos-algoritmos-quando-o-laborat%C3%B3rio-%C3%A9-o-mundo > Acesso em: 13/06/18.
CHENEY-LIPPOLD, John. We are Data: Algorithms and the Making of Our Digital Selves. New York University Press, 2017.
EYAL, Nir. Hooked: how to build habit-forming products. New York: Peguin Group, 2014.
FALTAY, Paulo. Algoritmos da paranoia: agência, subjetividade e controle, 2018. Disponível em: https://medialabufrj.net/
INTRONA, Lucas. The Algorithmic choreography of the impressionable subject. In: SEYFERT, R.; ROBERGE, J. Algorithmic Cultures: essays on meaning, performance and new Technologies. New York: Routledge, 2016.
NADLER, Anthony; MCGUIGAN, Lee. An impulse to exploit: the behavioral turn in data-drive marketing. Critical Studies in Media Communication, October, 2017.
SEAVER, Nick. Captivating algorithms: recommender systems as traps. Journal of Material Culture, August, 2018.
SEYFERT, Robert; ROBERGE, Jonathan. Algorithmic Cultures: essays on meaning, performance and new Technologies. New York: Routledge, 2016.
STARK, Luke. Algorithmic psychometrics and the scalable subject. Social Studies of Science, Vol. 48(2), p. 204-231, 2018.
ZUBOFF, Shoshana. Big Other: Surveillance Capitalism and the Prospects of an Information Civilization. Journal of Information Technology, n. 30, pp.75–89, 2015.
_______. Secrets of Surveillance Capitalism, 2016. Disponível em: <http://www.faz.net/aktuell/feuilleton/debatten/the-digital-debate/shoshana-zuboff-secrets- of-surveillance-capitalism-14103616.html?printPagedArticle=true#pageIndex_2 > Acesso em: 04/04/18.
_____. The Age of Surveillance Capitalism: The Fight for a Human Future ate the New Frontier of Power. PublicAffairs: New York, 2019.
//
Notas
[1] Disponível em: https://video.foxnews.com/v/1470704607001/#sp=show-clips
[2] Tradução livre de: Surveillance capitalism unilaterally claims human experience as free raw material for translation into behavioral data. Although some of these data are applied to product or service improvement, the rest are declared as a proprietary behavioral surplus, fed into advanced manufacturing processes known as “machine intelligence,” and fabricated into prediction products that anticipate what you will do now, soon, and later. Finally, these prediction products are traded in a new kind of marketplace for behavioral predictions that I call behavioral futures markets. (…) the competitive dynamics of these new markets drive surveillance capitalists to acquire ever-more-predictive sources of behavioral surplus: our voices, personalities, and emotions. Eventually, surveillance capitalists discovered that the most-predictive behavioral data come from intervening in the state of play in order to nudge, coax, tune, and herd behavior toward profitable outcomes. Competitive pressures produced this shift, in which automated machine processes not only know our behavior but also shape our behavior at scale. With this reorientation from knowledge to power, it is no longer enough to automate information flows about us; the goal now is to automate us. In this phase of surveillance capitalism’s evolution, the means of production are subordinated to an increasingly complex and comprehensive “means of behavioral modification.” (ZUBOFF, 2019, p. 14-15)
[3] Disponível em: https://mashable.com/2014/04/26/big-data-pregnancy/#WT117ytgq8qg
[4] Ver mais sobre o caso do Cambridge Analytica e as eleições americanas em 2016.
Esse texto faz parte do projeto ECONOMIA PSÍQUICA DOS ALGORITMOS: RACIONALIDADE, SUBJETIVIDADE E CONDUTA EM PLATAFORMAS DIGITAIS, coordenado pela profª Fernanda Bruno, com a apoio do CNPq. A pesquisadora Anna Bentes é bolsista da CAPES.